Since its release by Facebook in 2015, the name GraphQL has been frequently mentioned by the developer community when building APIs. So, what is GraphQL? How powerful is it that it attracts so much attention? Let’s learn about it through the following article.
This article is divided into two parts: in the first part, we will learn what GraphQL is, its features, and its advantages and disadvantages; in the second part, we will dive into building a simple GraphQL server on the NodeJS and Express platform.
Table of Contents
1. What is GraphQL?
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
GraphQL was developed internally by Facebook in 2012 before going public in 2015.
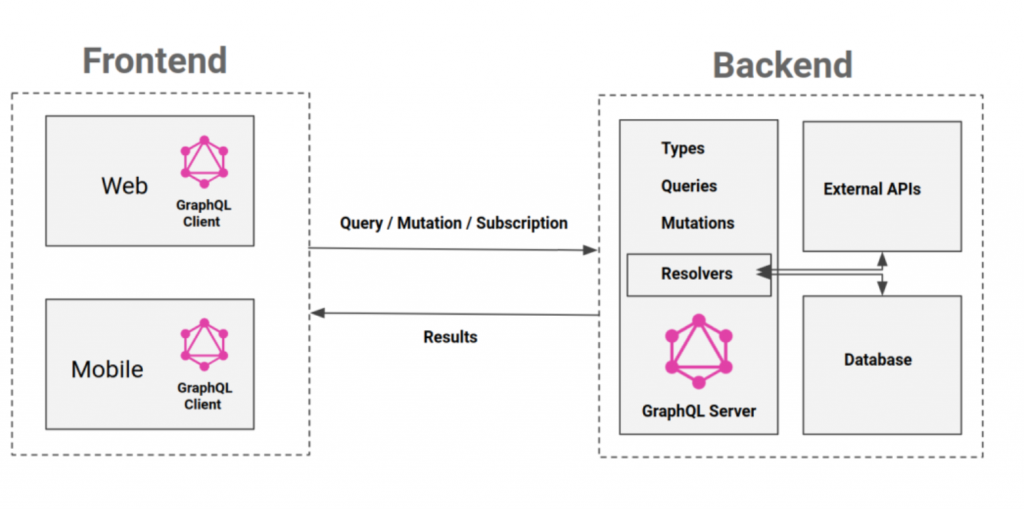
2. Core Feature
2.1 Queries
In simple phrases, “field” is the element of an object that we want to get from the server when performing operations such as querying, etc. In the above example, the corresponding fields are id, name, and category.
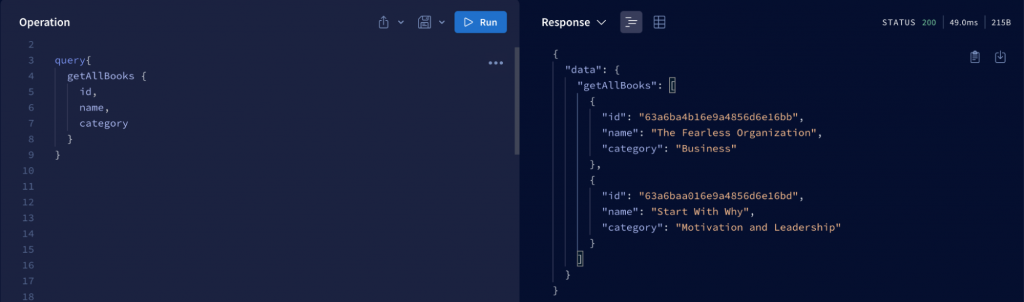
We have given our query a name GetAllBooks which is quite descriptive. Queries can also contain comments. Each line of comment must start with the # sign.
2.1.1 Field
Fields are basically parts of an object we want to retrieve from a server. In the query above, id, name, category is a field on the getAllBooks object.
2.1.2 Arguments
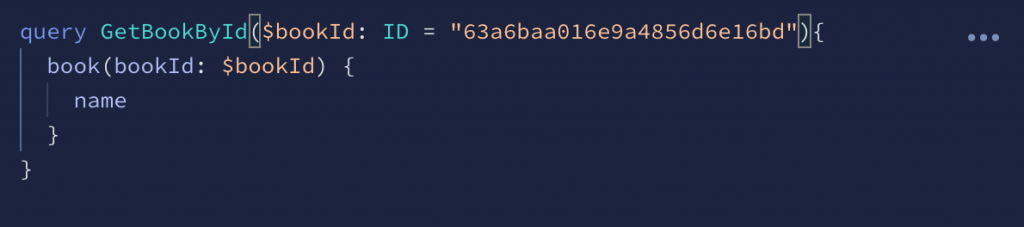
Just like functions in programming languages can accept arguments, a query can accept arguments. Arguments can be either optional or required. So we can rewrite our query to accept the ID of the author as an argument.

2.1.3 Variables
In addition to arguments, a query can also have variables to manipulate the data in a more concise way. Variables can be declared after the query or mutation and passed as arguments to a function, starting with $.

Variables can also have default values:
Like argument, variables can be required or optional. For required variables, an exclamation mark (!) must be added when defining the variable (including in the schema map).
2.1.4 Aliases
Aliases are created to help the client request data from the same field with different parameters in the same request.
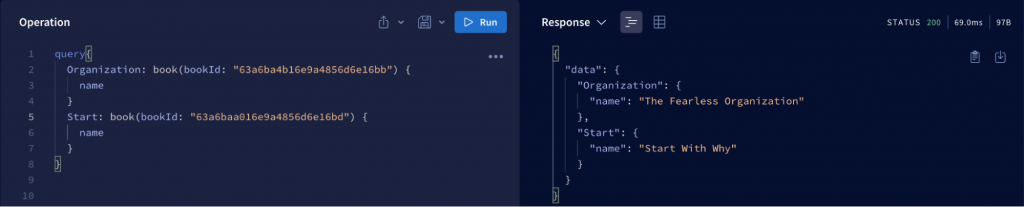
In the above example, the two book properties will conflict and it will not be possible to fetch the information by id without using Aliases to name them.
2.1.5 Fragments
Fragments are reusable set of fields that can be included in queries as needed. Assuming we need to fetch a bookDetail field on the book object, we can easily do that with:
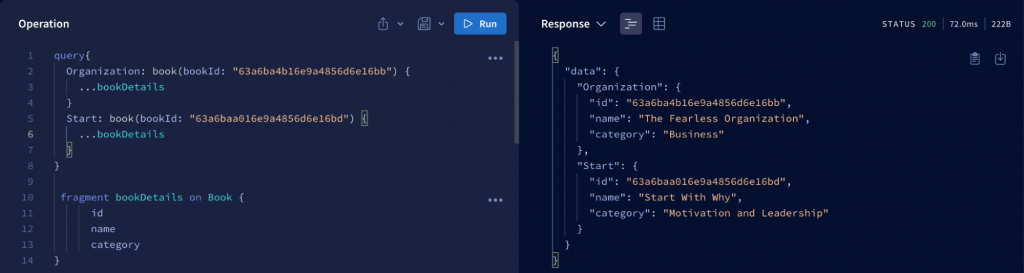
The components of a fragment include:
- Name: The name of the fragment.
- Object: The type of object the fragment is used for (in the example above, it is Book).
- Field: The reusable data fields.
2.1.6 Directives
Directives allow us to change the structure of a query flexibly using variables. GraphQL has two directives:
- @include will include a field or fragment when the if parameter is true.
- @skip will skip a field or fragment when the if parameter is false. Both directives accept a boolean type parameter.
2.2 Mutations
In GraphQL, adding or modifying data with the server is done through mutations. It corresponds to POST, PUT, and DELETE actions in REST APIs.
The example below is the mutation syntax that allows us to add a new Book record to the database with the function name createBook.
We send data as a payload in a mutation. For our example mutation, we could send the following data as payload. And we’ll get the following response after the update has been made on the server:
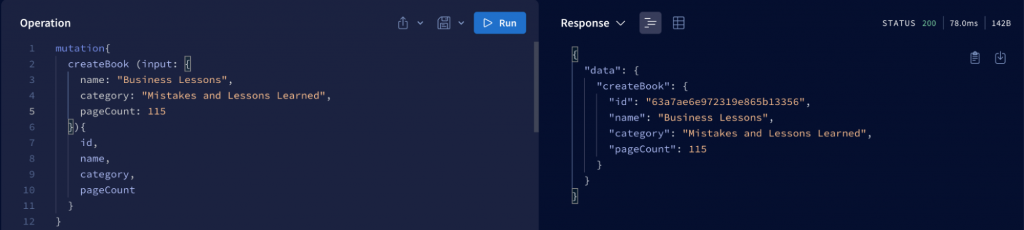
An important difference between mutations and queries is that mutations are executed sequentially to ensure data integrity, while queries are executed in parallel.
2.3 Subscriptions – Realtime updates
One of the important requirements for building and developing any product is real-time connectivity, to be able to connect to the server to get information about events immediately. In this case, GraphQL provides concepts called subscriptions.
When a client subscribes to an event, it begins to create and maintain connections to the server. Whenever that event occurs, the server listens and sends back information to the client. Unlike Queries and Mutations, which follow a “request-response-cycle,” Subscriptions represent a stream of data sent to the client.
Subscriptions are written using the same syntax as Queries and Mutations. The following example is the result of successfully subscribing to the addBook event.
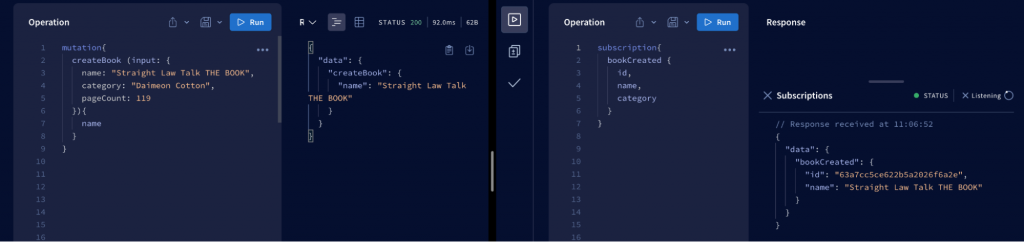
After the client sends a subscription to the server, a connection is opened between them. Then, whenever a bookCreated mutation is created, the server will send information about that user to the client.
3. GraphQL Clients
GraphQL Client is developed to not only optimize the features of GraphQL but also add many new modules to help clients have more options for their projects. Some prominent utilities that many GraphQL clients have developed include:
- Support cache feature to optimize requests.
- User interface management, convenient GraphQL schema.
- Support for environment variables.
- Manage request history.
- Free and open source.
- …
The popular GraphQL clients are being widely used to support many different platforms such as Apollo Client, Relay,..
4. GraphQL Servers
GraphQL servers consist of 2 main parts:
- Schema: Schema is understood as a description of what the server is capable of providing. It is like a contract between the client and the server, ensuring that the data requirements are always met.
- Resolver: Simply apprehended, it is as a function or method to process data for fields when receiving requests from the client.
Every time the server receives a request, the process will take place as follows:
- Parsing.
- Determining the operation to perform.
- Authenticating the request and returning an error if it fails.
- Performing the operation (query/mutation/subscription).
5. GraphQL vs REST
|
GraphQL |
REST |
|
API query language |
A concept, a type of architecture that defines a set of constraints and rules that must be followed when designing a web service. |
|
Only uses a single endpoint and the client can decide which types of data they need. |
Uses multiple different endpoints to query, typically each endpoint will return a single resource. |
|
Client-oriented architecture |
Client-oriented architecture |
|
Does not support caching mechanism
|
Supports caching mechanism
|
|
No API versioning required |
Supports multiple API versions |
|
Response output in JSON |
Response output usually in XML, JSON, and YAML |
6. Pros and Cons
6.1 Pro
- Speed: Compared to REST, GraphQL is quite fast because it only retrieves the exact data that the client requests.
- Single endpoint: Using only one endpoint.
- Versioning: GraphQL addresses issues related to the versioning of the API. We can add fields and types at any time without affecting current queries.
- ..
6.2 Cons
- Status 200: GraphQL always returns a status 200 whether the query was successful or not, which adds difficulty in error resolution.
- No cache: GraphQL does not support caching.
- Many open source GraphQL extensions are not compatible and cannot work with REST APIs.
- ..
Link: https://graphql.org/
Link: https://hasura.io/learn/graphql/intro-graphql/introduction/
7. Build simple GraphQL API Server với NodeJS và Express
In part 2, I will guide you through building a GraphQL API Server using the Apollo server on the NodeJS and Express platform to better understand the strengths of GraphQL.
Step 1: Create a new project
- mkdir graphql-server-demo
- cd graphql-server-demo
- npm init
Step 2: Install package
Currently, there are many implementations to build a graphql server such as Apollo GraphQL, Hasura, Hot Chocolate… And in this article, I will use Apollo GraphQL to set up. In addition, we also need to install the necessary libraries to create the easiest Graphql Server.
- mongoose
- graphql
- apollo-server-express
- apollo-server-core
- ws
- graphql-ws
- graphql-subscriptions
- graphql-tools/schema
In addition, you can install nodemon to make coding more convenient. After installation is complete, below are all the necessary packages to set up a GraphQL API server using MongoDB.
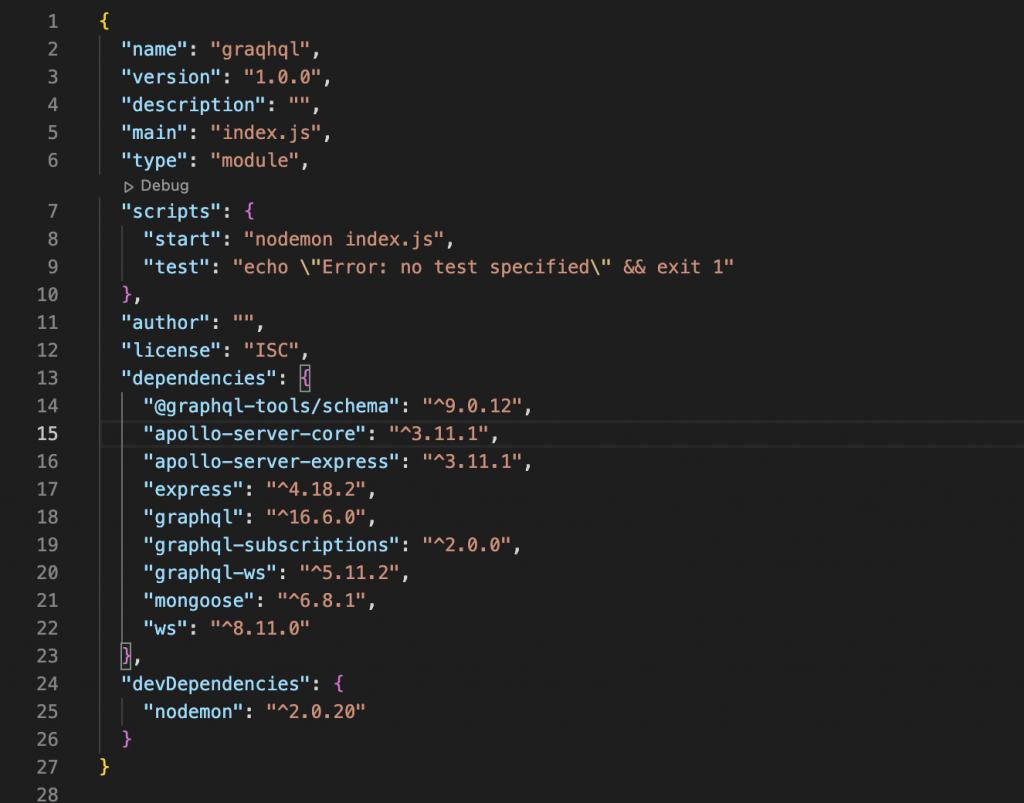
Step 3: Create structure folder
Next, we need to build a folder structure for the application to manage the project more easily. Here is the structure I have built for you to refer to:
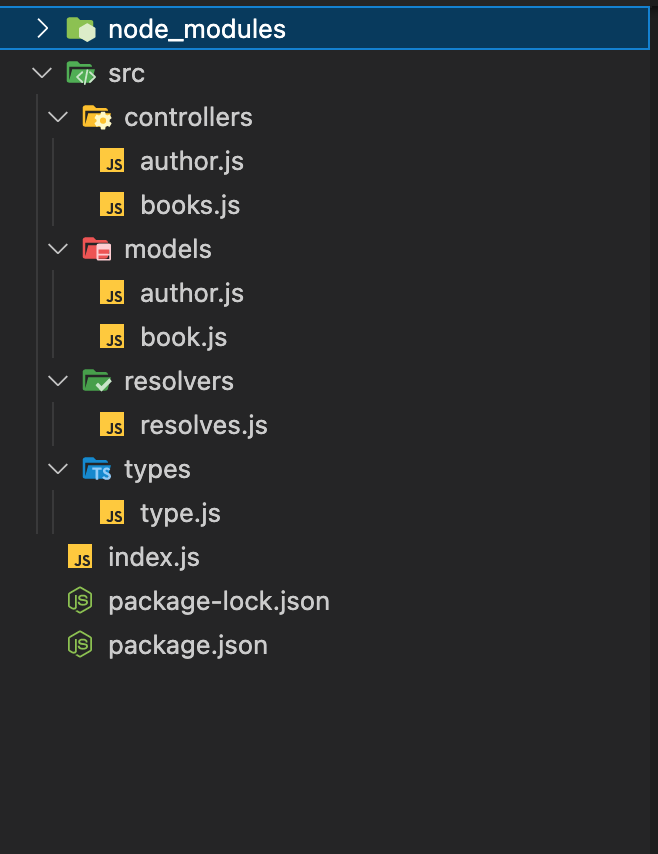
Step 4: Init server
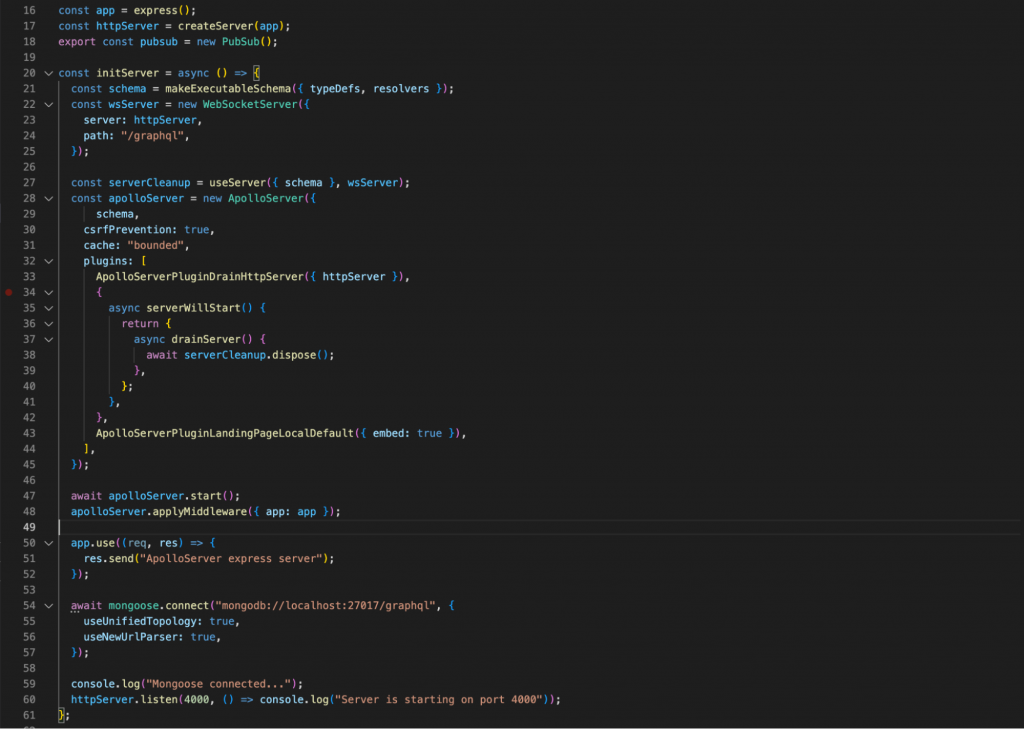
First, we need to build a function to start the server. Here are all the configurations for initializing ApolloServer v3 and connecting to MongoDB.
For detailed instructions, you can refer to this link to set it up as easily as possible.
https://www.apollographql.com/docs/apollo-server/v3/getting-started
Step 5: Defines GraphQL schema
GraphQL schema
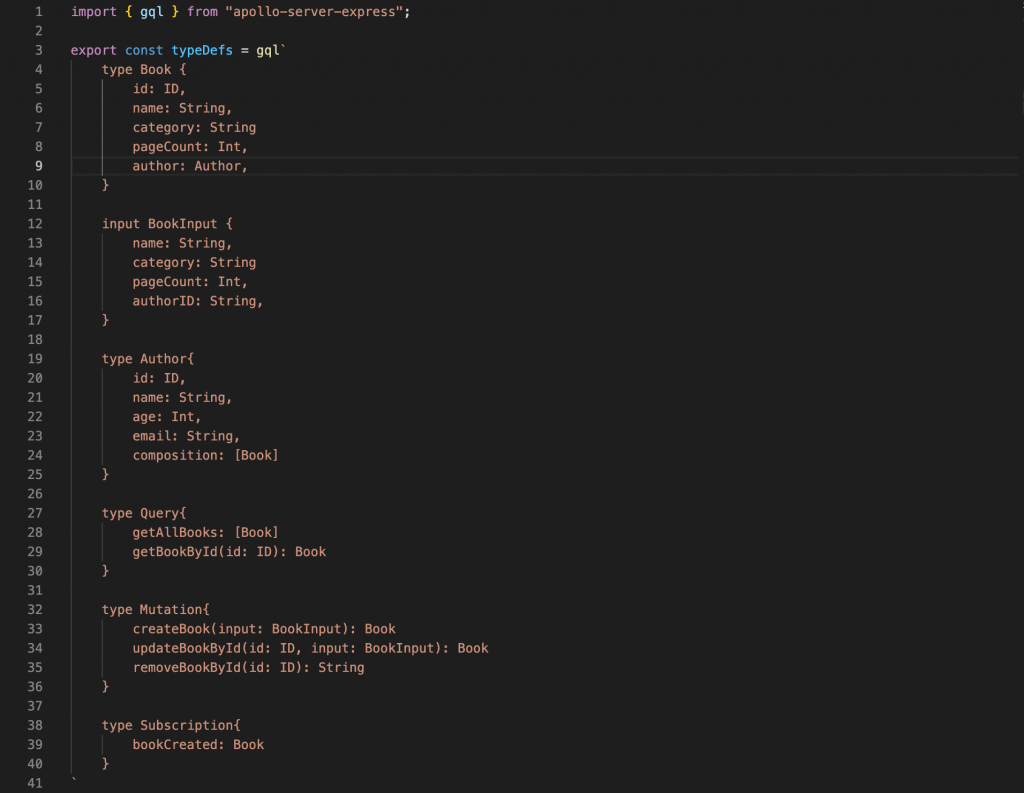
The field and data type for Author and Book
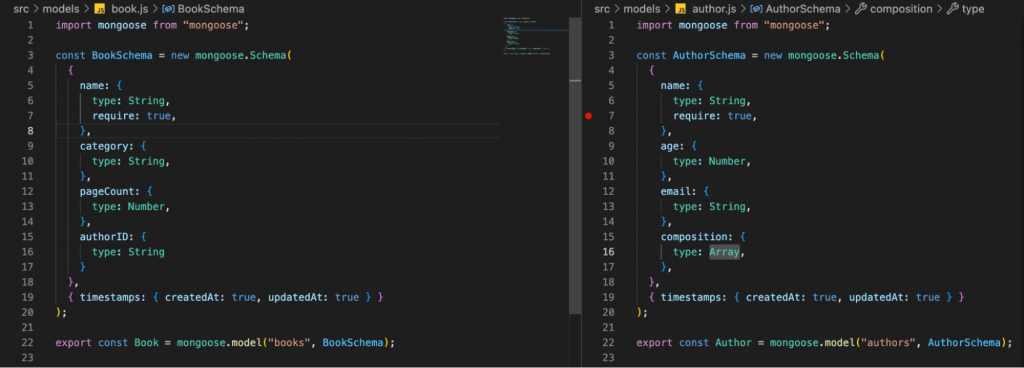
Step 6: Define resolver
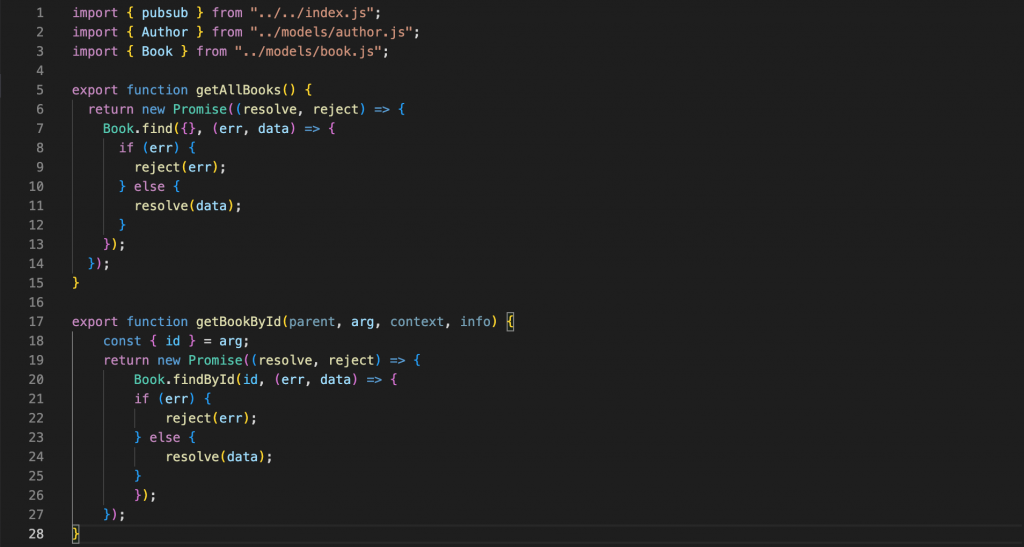
In order for the Graphql Server to accurately send the data that the client requests, in addition to defining the schema, it is important to define resolvers. This means that the server describes the behavior of listening and performing queries on the database to retrieve information and return it to the client. In this example, we define functions to handle queries, mutations, and subscriptions
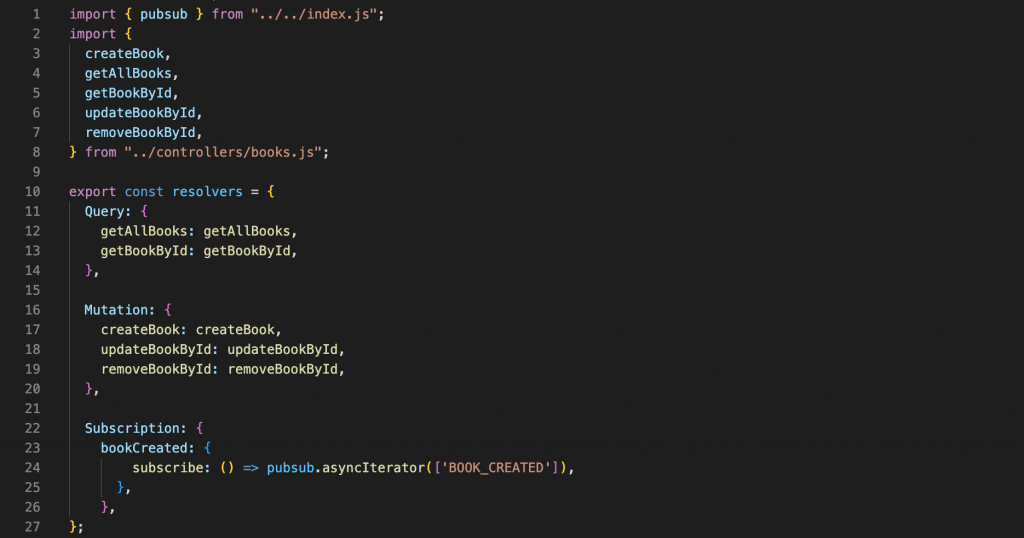
The getAllBooks and getBookById functions return data when the user manipulates the query.
The createBook, updateBookById, and removeBook functions handle when the client performs the CREATE, UPDATE, and DELETE actions for the book permissions. And the analogy for the object is Author.
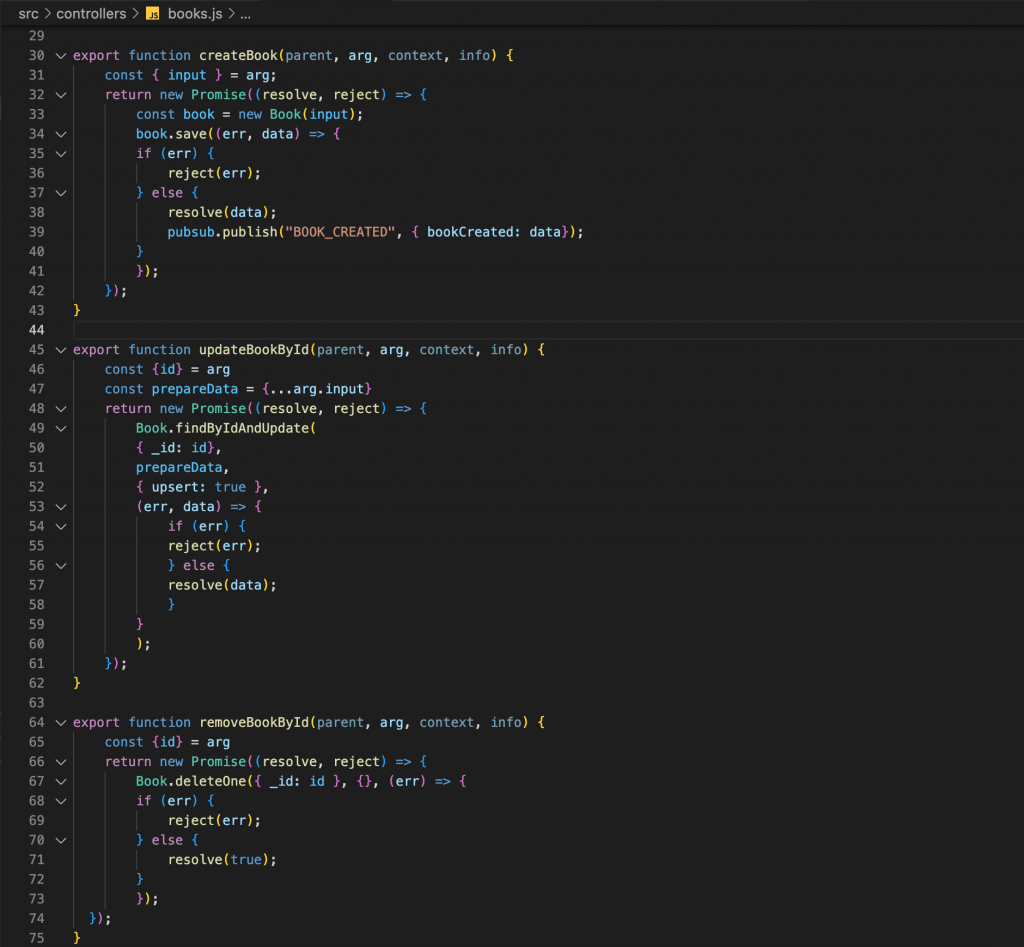
Just now is the whole process to build a GraphQL server using Apollo Server. Here we test together to see the results.
Query
On the client side, for quick and convenient operation, I will use the apollographql sandbox studio to interact with data through the server we just set up above. First, with the query feature
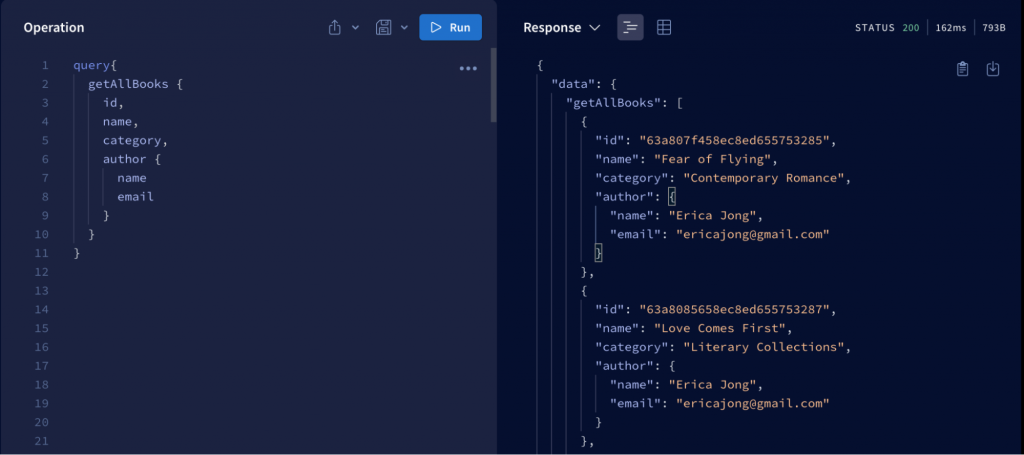
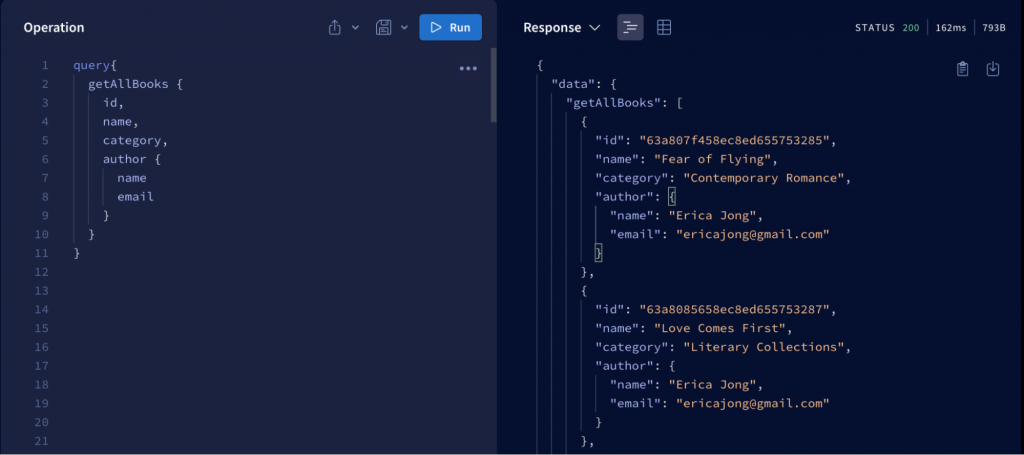
In the example above, through the query operation, we were able to get all the information about the books along with the corresponding author information. The result also clearly shows the prominent feature of GraphQL, which is that it only retrieves the information that the client requests.
Mutation
With the knowledge in part 1, we’ve already known that the mutation feature allows the client to write data to the server to perform actions like (CREATE, UPDATE, and DELETE)
In this example, we add 1 record containing Author information to the server.
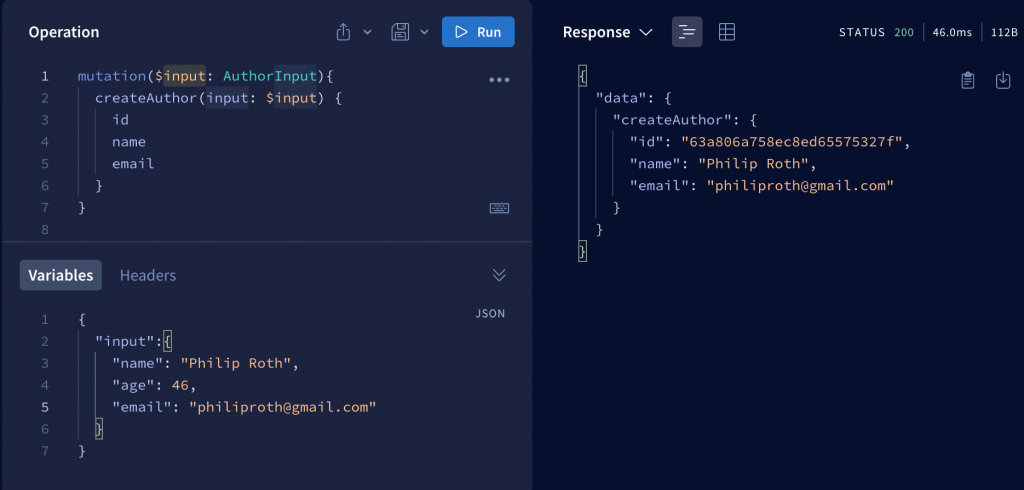
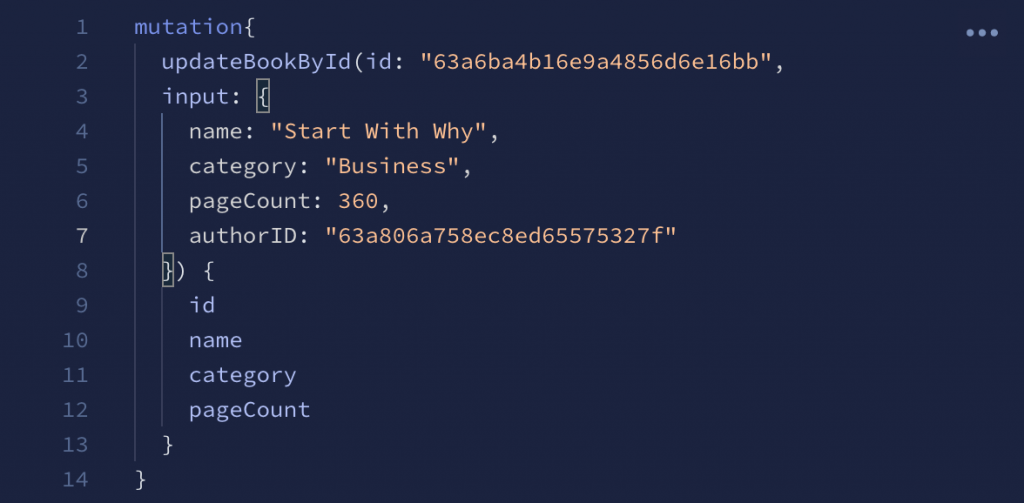
In addition to passing variables like in the example, you can use arguments to directly assign data
Subscription
To reiterate a bit about the subscription feature, it allows the client to register events with the server side using the subscription syntax then a connection will be created. And when the event occurs, it sends information so that we can perform other actions in real-time. In this example, I use a subscription to create a connection to listen for signals when the client adds a new record to the server.
In this example, I use a subscription to create a connection that listens for signals when the client adds a new record to the server.
In the Subscription resolver, there should be a function to subscribe with the message ‘BOOK_CREATED’

In addition, in the addBook function, when adding a record to the database successfully, we also need to configure a signal for the subscription to listen for the event that has been sent.
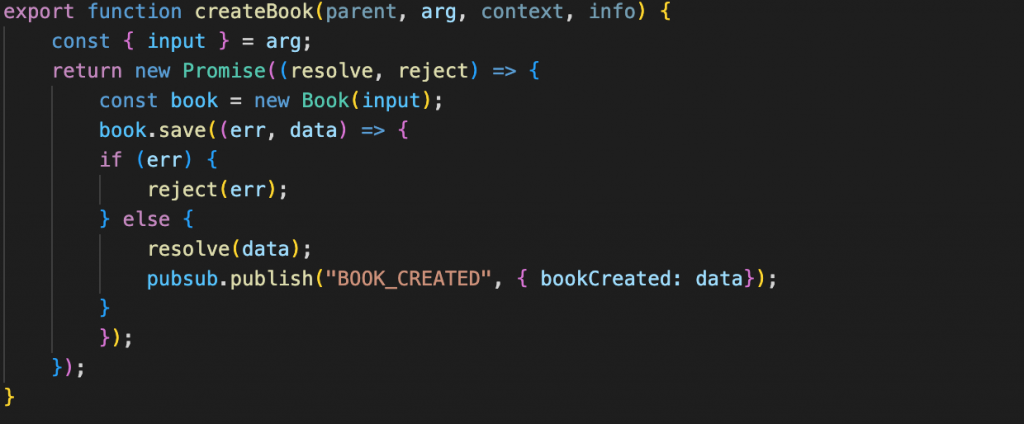
And finally, let’s take a look at the results through the graphqlserver sandbox. Here I am in two tabs to observe when performing the insert book mutation into the database, the subscription also immediately sends out the previously subscribed event information.
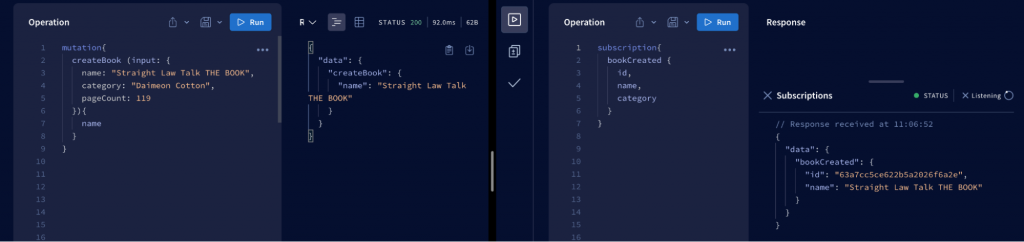
This is the end of the steps to build a GraphQL server using Node.js and Express. It is quite simple, isn’t it?
Good luck to everyone.
HieuPV