When working with relational databases, one of the most critical elements for improving query performance is the use of indexes. Indexes play a pivotal role in speeding up data retrieval, much like the index at the back of a book helps you locate specific information without flipping through every page. Without indexes, databases would need to perform a full table scan for each query, which is both inefficient and time-consuming, especially as data grows.
Table of Contents
What Is a Database Index?
In a database, an index is a data structure that allows quick lookup of records in a table. By reducing the amount of data that needs to be scanned, indexes can dramatically speed up query operations. While the primary goal of an index is to improve performance, it’s important to note that maintaining an index incurs storage costs and can slow down insert and update operations.
There are various types of indexes, but the two most commonly used are hash indexes and B-tree indexes. Each has its unique strengths, and knowing when to use one over the other is essential for effective database optimization.
Hash Index
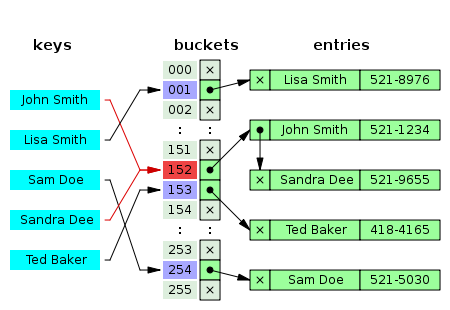
A hash index uses a hash function to map data to a fixed-size array of buckets. When you search for a value, the hash function is applied to the search key, which quicklydirects the query to the appropriate bucket where the data is stored.
Hash indexes work by converting the index key into a smaller integer or a value within a fixed range using a hash function. This output is then used to identify the location where the data is stored, avoiding the need to scan the entire dataset. Hash indexes are particularly fast for equality comparisons (such as = or IN queries), as the hash function provides an exact match. However, they do not support range queries (like <, >, or BETWEEN) because the hash values are not stored in any particular order.
Hash indexes are ideal when you have a high volume of lookups that require exact matches, such as searching for a specific user ID or email address. They work well when range queries are unnecessary, as hash indexes are not suitable for retrieving data between a range of values. They are also useful in environments with static or low-write workloads, as they may not perform as well when data is frequently updated.
Despite their advantages, hash indexes have certain limitations. They do not support range queries, meaning if you need to perform searches like “find all orders between $100 and $200,” hash indexes won’t help. Additionally, because hash functions scatter values into different buckets, there is no inherent order to the data, which requires additional processing for sorting.
B-Tree Index
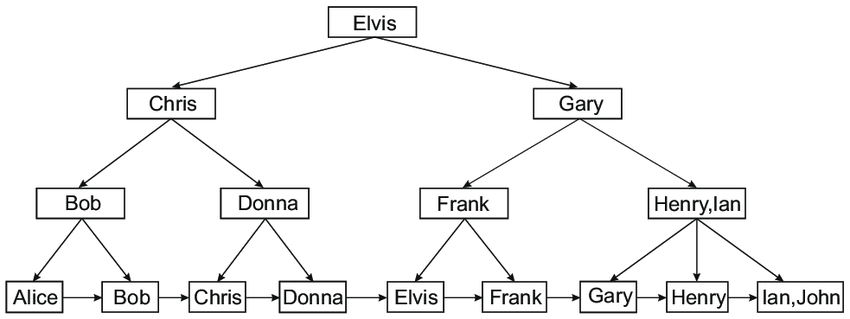
The B-tree (Balanced Tree) index is the most widely used indexing method in databases. Unlike hash indexes, B-tree indexes store data in a hierarchical tree structure, where everynode represents a range of values. This structure makes B-tree indexes well-suited for a variety of query types, including both exact lookups and range queries.
In a B-tree, data is stored in sorted order, allowing the database to quickly traverse the tree to locate a specific key. This structure ensures that B-tree indexes excel at handling range queries because they can efficiently retrieve data within a specific range of values. The B-tree’s self-balancing nature ensures that operations like searching, inserting, and deleting occur efficiently, even as data grows.
B-tree indexes are versatile and can handle general-purpose queries, including exact lookups and range queries. They are particularly useful when you need to sort data by a particular field, such as retrieving records in ascending or descending order. They also perform well in OLTP (Online Transaction Processing) environments where tables are frequently updated, as B-trees handle inserts and updates efficiently while maintaining data order.
The key advantages of B-tree indexes are their ability to handle range queries and ordered data efficiently. However, they are generally slower than hash indexes for exact match queries.
Choosing Between Hash Indexes and B-Tree Indexes
The choice between a hash index and a B-tree index largely depends on the nature of your queries and the workload of your database.
If your queries mostly involve exact matches and you don’t require range queries, a hash index can be extremely efficient. However, if your queries involve range queries or need to return ordered data, then a B-tree index is the better choice.
Conclusion
Indexes are an indispensable part of any relational database, and understanding when to use hash indexes versus B-tree indexes can make a significant difference in query performance. By tailoring your index design to the nature of your queries, you can ensure faster data retrieval and more efficient resource utilization.
For those serious about mastering database optimization, I highly recommend the book Relational Database Index Design and the Optimizers by Tapio Lahdenmaki and Mike Leach. This book gives you everything you need to understand how indexes work and offers detailed insights into index design strategies, making it an essential resource for developers and database administrators aiming to optimize database performance.